10.10. Life Cycle Assessment of an inductor (student version)#
Written by Félix Pollet, ISAE-Supaéro, France
The objective of this notebook is to conduct a life cycle assessment (LCA) on the inductor to evaluate its environmental impact over several categories such as climate change and depletion of material resources, among others.
In a second step, you will re-run the optimization process from notebook 06_SizingCodeInductor with an environmental objective function instead of a mass minimization objective, and observe the changes in the design.
10.10.1. 1. Scope definition of the LCA#
The first step in conducting an LCA is to define the scope of the study. We have to clearly state :
The goal of the study, here it is to evaluate the environmental impacts of the inductor and minimize these impacts by resizing the inductor.
The functional unit, which represents a quantified description of the system and its performance.
The boundaries of the system, i.e. what is covered by the study and what is not.
Any other valuable information or assumption.
Once the scope has been defined, you may build a process tree, which is a hierarchical representation of the materials and energy required to fulfill the functional unit.
Exercise (Scope definition)
Provide a definition for the functional unit of the inductor and the boundaries of the system. Build the associated process tree.
10.10.2. 2. Data for the LCA#
Collecting data for a Life Cycle Inventory can be a time-consuming process. In this study, we will rely on a pre-existing database that directly provides the impacts associated with the production of the coil and the ferromagnetic core. This includes the entire production chain, from raw material extraction to the final product, including transportation from one site to another. In addition, the database provides the environmental impacts resulting from the production of 1 kWh of electricity, using the French electricity mix. This is useful to take into account the impact of energy losses.
Exercise (Get familiar with LCA data)
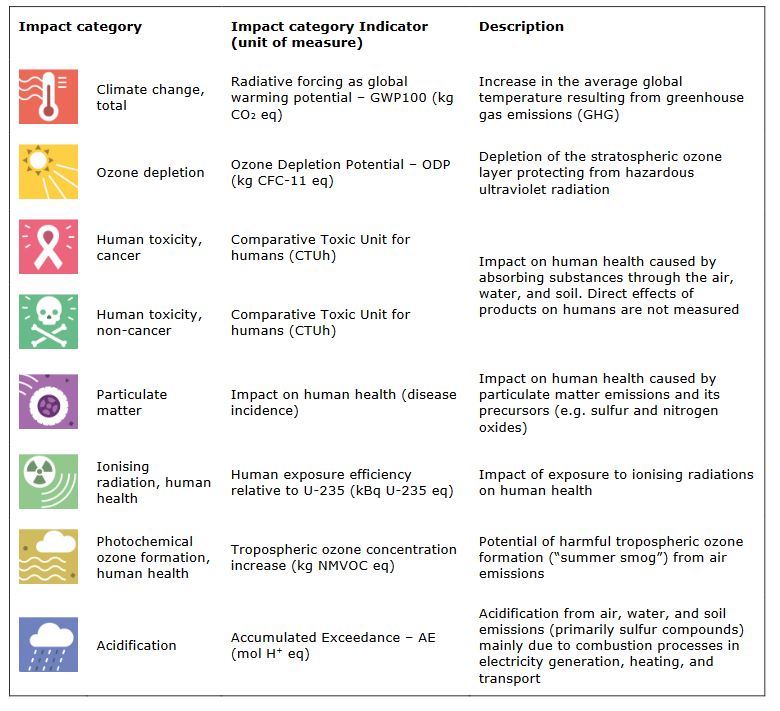
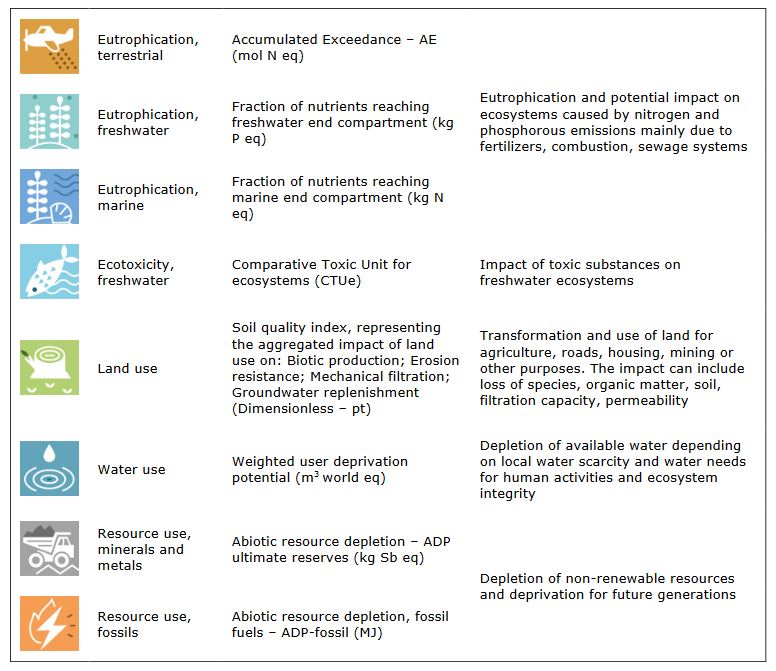
The following lines import the databases and display the data over 16 impact categories, including climate change, particulate matter formation, and material resources depletion.
Beware, the impacts are provided for 1 kg of final product, or, for the electricity, 1 kWh of electricity production.
Have a first look at the impacts generated by the production of each component. Be curious about what represent each impact.
Supplementary information on the impact categories:
# Import libraries
import pandas as pd
from IPython import display as ICD
import importlib
# Path to the database
database_path = 'https://raw.githubusercontent.com/SizingLab/sizing_course/main/laboratories/Lab-watt_project/assets/data/lca_inductance.xlsx'
# Read LCA data for each "background" data of the process tree
df_copper = pd.read_excel(database_path, sheet_name='Copper wire (1 kg)')
df_ferrite = pd.read_excel(database_path, sheet_name='Ferrite (1 kg)')
df_electricity = pd.read_excel(database_path, sheet_name='Electricity France (1 kWh)')
# Display LCA results for each "background" data
print("LCA for the production of 1 kg of copper"); ICD.display(df_copper)
print("LCA for the production of 1 kg of ferrite"); ICD.display(df_ferrite)
print("LCA for the production of 1 kWh of electricity (France)"); ICD.display(df_electricity)
LCA for the production of 1 kg of copper
| Impact category | Indicator | Impact Score | Unit | |
|---|---|---|---|---|
| 0 | acidification | accumulated exceedance (AE) | 5.816810e-01 | mol H+-Eq |
| 1 | climate change | global warming potential (GWP100) | 7.433720e+00 | kg CO2-Eq |
| 2 | ecotoxicity: freshwater | comparative toxic unit for ecosystems (CTUe) | 6.632250e+02 | CTUe |
| 3 | energy resources: non-renewable | abiotic depletion potential (ADP): fossil fuels | 9.333420e+01 | MJ, net calorific value |
| 4 | eutrophication: freshwater | fraction of nutrients reaching freshwater end ... | 4.579140e-02 | kg P-Eq |
| 5 | eutrophication: marine | fraction of nutrients reaching marine end comp... | 2.856350e-02 | kg N-Eq |
| 6 | eutrophication: terrestrial | accumulated exceedance (AE) | 3.980400e-01 | mol N-Eq |
| 7 | human toxicity: carcinogenic | comparative toxic unit for human (CTUh) | 8.789730e-08 | CTUh |
| 8 | human toxicity: non-carcinogenic | comparative toxic unit for human (CTUh) | 7.687160e-06 | CTUh |
| 9 | ionising radiation: human health | human exposure efficiency relative to u235 | 8.552100e-01 | kBq U235-Eq |
| 10 | land use | soil quality index | 1.848175e+02 | dimensionless |
| 11 | material resources: metals/minerals | abiotic depletion potential (ADP): elements (u... | 7.467610e-03 | kg Sb-Eq |
| 12 | ozone depletion | ozone depletion potential (ODP) | 8.562390e-08 | kg CFC-11-Eq |
| 13 | particulate matter formation | impact on human health | 1.322611e-06 | disease incidence |
| 14 | photochemical oxidant formation: human health | tropospheric ozone concentration increase | 1.136106e-01 | kg NMVOC-Eq |
| 15 | water use | user deprivation potential (deprivation-weight... | 6.310940e+00 | m3 world eq. deprived |
LCA for the production of 1 kg of ferrite
| Impact category | Indicator | Impact Score | Unit | |
|---|---|---|---|---|
| 0 | acidification | accumulated exceedance (AE) | 1.467400e-02 | mol H+-Eq |
| 1 | climate change | global warming potential (GWP100) | 2.073400e+00 | kg CO2-Eq |
| 2 | ecotoxicity: freshwater | comparative toxic unit for ecosystems (CTUe) | 2.390300e+01 | CTUe |
| 3 | energy resources: non-renewable | abiotic depletion potential (ADP): fossil fuels | 2.272700e+01 | MJ, net calorific value |
| 4 | eutrophication: freshwater | fraction of nutrients reaching freshwater end ... | 8.475800e-04 | kg P-Eq |
| 5 | eutrophication: marine | fraction of nutrients reaching marine end comp... | 3.329300e-03 | kg N-Eq |
| 6 | eutrophication: terrestrial | accumulated exceedance (AE) | 3.572600e-02 | mol N-Eq |
| 7 | human toxicity: carcinogenic | comparative toxic unit for human (CTUh) | 9.170400e-08 | CTUh |
| 8 | human toxicity: non-carcinogenic | comparative toxic unit for human (CTUh) | 2.892800e-08 | CTUh |
| 9 | ionising radiation: human health | human exposure efficiency relative to u235 | 1.620100e-01 | kBq U235-Eq |
| 10 | land use | soil quality index | 1.047100e+01 | dimensionless |
| 11 | material resources: metals/minerals | abiotic depletion potential (ADP): elements (u... | 6.671600e-06 | kg Sb-Eq |
| 12 | ozone depletion | ozone depletion potential (ODP) | 1.359400e-08 | kg CFC-11-Eq |
| 13 | particulate matter formation | impact on human health | 1.566600e-07 | disease incidence |
| 14 | photochemical oxidant formation: human health | tropospheric ozone concentration increase | 1.121300e-02 | kg NMVOC-Eq |
| 15 | water use | user deprivation potential (deprivation-weight... | 3.686100e-01 | m3 world eq. deprived |
LCA for the production of 1 kWh of electricity (France)
| Impact category | Indicator | Impact Score | Unit | |
|---|---|---|---|---|
| 0 | acidification | accumulated exceedance (AE) | 3.318000e-04 | mol H+-Eq |
| 1 | climate change | global warming potential (GWP100) | 7.769200e-02 | kg CO2-Eq |
| 2 | ecotoxicity: freshwater | comparative toxic unit for ecosystems (CTUe) | 3.723700e-01 | CTUe |
| 3 | energy resources: non-renewable | abiotic depletion potential (ADP): fossil fuels | 1.161900e+01 | MJ, net calorific value |
| 4 | eutrophication: freshwater | fraction of nutrients reaching freshwater end ... | 1.533300e-05 | kg P-Eq |
| 5 | eutrophication: marine | fraction of nutrients reaching marine end comp... | 9.840600e-05 | kg N-Eq |
| 6 | eutrophication: terrestrial | accumulated exceedance (AE) | 7.263700e-04 | mol N-Eq |
| 7 | human toxicity: carcinogenic | comparative toxic unit for human (CTUh) | 4.926400e-11 | CTUh |
| 8 | human toxicity: non-carcinogenic | comparative toxic unit for human (CTUh) | 1.099000e-09 | CTUh |
| 9 | ionising radiation: human health | human exposure efficiency relative to u235 | 5.266300e-01 | kBq U235-Eq |
| 10 | land use | soil quality index | 3.482100e-01 | dimensionless |
| 11 | material resources: metals/minerals | abiotic depletion potential (ADP): elements (u... | 6.396600e-07 | kg Sb-Eq |
| 12 | ozone depletion | ozone depletion potential (ODP) | 3.139500e-09 | kg CFC-11-Eq |
| 13 | particulate matter formation | impact on human health | 4.493600e-09 | disease incidence |
| 14 | photochemical oxidant formation: human health | tropospheric ozone concentration increase | 2.557400e-04 | kg NMVOC-Eq |
| 15 | water use | user deprivation potential (deprivation-weight... | 1.346600e-01 | m3 world eq. deprived |
10.10.3. 3. LCA of the sized inductor#
10.10.3.1. Impacts calculation#
Now that we know how much impacts correspond to the production of 1 kg of copper, 1 kg of ferrite pot, and 1 kWh of electricity, the next step is to calculate the total impact of the inductor. In this notebook, we will re-use the results obtained in notebook 07_SizingCodeInductor-Surrogate.
Exercise (Calculate the impacts for the inductor system)
Using the process tree, calculate the impacts of the inductor by summing the impacts of each subprocess.
# TO COMPLETE
# Values obtained with the sizing code
M_ferrite = ... # [kg]
M_copper = ... # [kg]
M_total = ... # [kg]
PJ = ... # [kW]
# Parameters for the life cycle assessment
Crr = 0.01 # [-] rolling resistance coefficient
E_J = ... # [kWh] Joules losses
E_fr = ... # [kWh] Friction losses at bus level due to inductor's mass
# Create a dictionary to store the LCA database of each component and the corresponding sizing parameters
dataframes_and_params = {
'Copper wire (1 kg)': {'df': df_copper, 'param': M_copper},
'Ferrite core (1 kg)': {'df': df_ferrite, 'param': M_ferrite},
'Joules losses': {'df': df_electricity, 'param': E_J},
'Friction losses': {'df': df_electricity, 'param': E_fr}
}
# Create an empty DataFrame to store the final results
result_df = pd.DataFrame(columns=["Impact category", "Indicator", "Unit"])
# Populate the result DataFrame with the impacts of each component
for component, data in dataframes_and_params.items():
df = data['df'].copy()
param = data['param']
# Multiply the "Impact Score" by the parameter
df['Impact Score'] *= param
# Rename the "Impact Score" column to include the name of the corresponding component
df.rename(columns={'Impact Score': f'Impact Score ({component.split()[0]})'}, inplace=True)
# Merge the DataFrames based on the common columns
result_df = pd.merge(result_df, df, how='outer', on=["Impact category", "Indicator", "Unit"])
# Calculate the total impact score by aggregating the impacts of each component
result_df['Impact Score (Total)'] = result_df.filter(like='Impact Score').sum(axis=1)
# Display the results
result_df
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[2], line 30
27 param = data['param']
29 # Multiply the "Impact Score" by the parameter
---> 30 df['Impact Score'] *= param
32 # Rename the "Impact Score" column to include the name of the corresponding component
33 df.rename(columns={'Impact Score': f'Impact Score ({component.split()[0]})'}, inplace=True)
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/generic.py:12104, in NDFrame.__imul__(self, other)
12102 def __imul__(self: NDFrameT, other) -> NDFrameT:
12103 # error: Unsupported left operand type for * ("Type[NDFrame]")
> 12104 return self._inplace_method(other, type(self).__mul__)
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/generic.py:12073, in NDFrame._inplace_method(self, other, op)
12068 @final
12069 def _inplace_method(self, other, op):
12070 """
12071 Wrap arithmetic method to operate inplace.
12072 """
> 12073 result = op(self, other)
12075 if (
12076 self.ndim == 1
12077 and result._indexed_same(self)
12078 and is_dtype_equal(result.dtype, self.dtype)
12079 ):
12080 # GH#36498 this inplace op can _actually_ be inplace.
12081 self._values[:] = result._values
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/ops/common.py:72, in _unpack_zerodim_and_defer.<locals>.new_method(self, other)
68 return NotImplemented
70 other = item_from_zerodim(other)
---> 72 return method(self, other)
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/arraylike.py:118, in OpsMixin.__mul__(self, other)
116 @unpack_zerodim_and_defer("__mul__")
117 def __mul__(self, other):
--> 118 return self._arith_method(other, operator.mul)
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/series.py:6259, in Series._arith_method(self, other, op)
6257 def _arith_method(self, other, op):
6258 self, other = ops.align_method_SERIES(self, other)
-> 6259 return base.IndexOpsMixin._arith_method(self, other, op)
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/base.py:1325, in IndexOpsMixin._arith_method(self, other, op)
1322 rvalues = ensure_wrapped_if_datetimelike(rvalues)
1324 with np.errstate(all="ignore"):
-> 1325 result = ops.arithmetic_op(lvalues, rvalues, op)
1327 return self._construct_result(result, name=res_name)
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/ops/array_ops.py:226, in arithmetic_op(left, right, op)
222 _bool_arith_check(op, left, right)
224 # error: Argument 1 to "_na_arithmetic_op" has incompatible type
225 # "Union[ExtensionArray, ndarray[Any, Any]]"; expected "ndarray[Any, Any]"
--> 226 res_values = _na_arithmetic_op(left, right, op) # type: ignore[arg-type]
228 return res_values
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/ops/array_ops.py:165, in _na_arithmetic_op(left, right, op, is_cmp)
162 func = partial(expressions.evaluate, op)
164 try:
--> 165 result = func(left, right)
166 except TypeError:
167 if not is_cmp and (is_object_dtype(left.dtype) or is_object_dtype(right)):
168 # For object dtype, fallback to a masked operation (only operating
169 # on the non-missing values)
170 # Don't do this for comparisons, as that will handle complex numbers
171 # incorrectly, see GH#32047
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/computation/expressions.py:241, in evaluate(op, a, b, use_numexpr)
238 if op_str is not None:
239 if use_numexpr:
240 # error: "None" not callable
--> 241 return _evaluate(op, op_str, a, b) # type: ignore[misc]
242 return _evaluate_standard(op, op_str, a, b)
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/computation/expressions.py:70, in _evaluate_standard(op, op_str, a, b)
68 if _TEST_MODE:
69 _store_test_result(False)
---> 70 return op(a, b)
TypeError: unsupported operand type(s) for *: 'float' and 'ellipsis'
10.10.3.2. Visualization and interpretation#
It is now possible to visualize the results over each impact category.
The following figure provides the results obtained over the impact categories, expressed in the physical units specific to each category.
# Plot the LCA results
result_df['XLabels'] = result_df['Impact category'] + ' (' + result_df['Unit'] + ')'
ax = result_df[['Impact Score (Copper)', 'Impact Score (Ferrite)', 'Impact Score (Joules)', 'Impact Score (Friction)']].plot.bar(stacked=True)
ax.set_xticklabels(result_df['XLabels'])
ax.set_xlabel("Impact Category")
ax.set_ylabel("Impact Score (unit specific to each category)")
ax.set_title("Impact Score for Each Impact Category");
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[3], line 3
1 # Plot the LCA results
2 result_df['XLabels'] = result_df['Impact category'] + ' (' + result_df['Unit'] + ')'
----> 3 ax = result_df[['Impact Score (Copper)', 'Impact Score (Ferrite)', 'Impact Score (Joules)', 'Impact Score (Friction)']].plot.bar(stacked=True)
4 ax.set_xticklabels(result_df['XLabels'])
5 ax.set_xlabel("Impact Category")
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/frame.py:3813, in DataFrame.__getitem__(self, key)
3811 if is_iterator(key):
3812 key = list(key)
-> 3813 indexer = self.columns._get_indexer_strict(key, "columns")[1]
3815 # take() does not accept boolean indexers
3816 if getattr(indexer, "dtype", None) == bool:
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/indexes/base.py:6070, in Index._get_indexer_strict(self, key, axis_name)
6067 else:
6068 keyarr, indexer, new_indexer = self._reindex_non_unique(keyarr)
-> 6070 self._raise_if_missing(keyarr, indexer, axis_name)
6072 keyarr = self.take(indexer)
6073 if isinstance(key, Index):
6074 # GH 42790 - Preserve name from an Index
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/indexes/base.py:6130, in Index._raise_if_missing(self, key, indexer, axis_name)
6128 if use_interval_msg:
6129 key = list(key)
-> 6130 raise KeyError(f"None of [{key}] are in the [{axis_name}]")
6132 not_found = list(ensure_index(key)[missing_mask.nonzero()[0]].unique())
6133 raise KeyError(f"{not_found} not in index")
KeyError: "None of [Index(['Impact Score (Copper)', 'Impact Score (Ferrite)',\n 'Impact Score (Joules)', 'Impact Score (Friction)'],\n dtype='object')] are in the [columns]"
It is not easy to read, right? This is because each impact category is expressed with its own unit, so that the values varies highly from one category to another.
What we can do is to have a look at the contributions, in percent, of each component (copper, ferrite and energy losses) across each impact category:
# Contributions
result_df_percent = result_df[['Impact Score (Copper)', 'Impact Score (Ferrite)', 'Impact Score (Joules)', 'Impact Score (Friction)']].apply(lambda x: x*100/sum(x), axis=1)
ax = result_df_percent[['Impact Score (Copper)', 'Impact Score (Ferrite)', 'Impact Score (Joules)', 'Impact Score (Friction)']].plot.bar(stacked=True)
ax.set_xticklabels(result_df['XLabels'])
ax.set_xlabel("Impact Category")
ax.set_ylabel("Contribution to Impact Score (%)")
ax.set_title("Contributions to Impact Score for Each Impact Category");
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[4], line 2
1 # Contributions
----> 2 result_df_percent = result_df[['Impact Score (Copper)', 'Impact Score (Ferrite)', 'Impact Score (Joules)', 'Impact Score (Friction)']].apply(lambda x: x*100/sum(x), axis=1)
3 ax = result_df_percent[['Impact Score (Copper)', 'Impact Score (Ferrite)', 'Impact Score (Joules)', 'Impact Score (Friction)']].plot.bar(stacked=True)
4 ax.set_xticklabels(result_df['XLabels'])
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/frame.py:3813, in DataFrame.__getitem__(self, key)
3811 if is_iterator(key):
3812 key = list(key)
-> 3813 indexer = self.columns._get_indexer_strict(key, "columns")[1]
3815 # take() does not accept boolean indexers
3816 if getattr(indexer, "dtype", None) == bool:
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/indexes/base.py:6070, in Index._get_indexer_strict(self, key, axis_name)
6067 else:
6068 keyarr, indexer, new_indexer = self._reindex_non_unique(keyarr)
-> 6070 self._raise_if_missing(keyarr, indexer, axis_name)
6072 keyarr = self.take(indexer)
6073 if isinstance(key, Index):
6074 # GH 42790 - Preserve name from an Index
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/indexes/base.py:6130, in Index._raise_if_missing(self, key, indexer, axis_name)
6128 if use_interval_msg:
6129 key = list(key)
-> 6130 raise KeyError(f"None of [{key}] are in the [{axis_name}]")
6132 not_found = list(ensure_index(key)[missing_mask.nonzero()[0]].unique())
6133 raise KeyError(f"{not_found} not in index")
KeyError: "None of [Index(['Impact Score (Copper)', 'Impact Score (Ferrite)',\n 'Impact Score (Joules)', 'Impact Score (Friction)'],\n dtype='object')] are in the [columns]"
Exercise 1 (Contributions)
For each impact category, what are the main contributors?
What would you expect if we had to re-size the inductor in order to minimize these impacts?
Exercise 2 (Most relevant impacts?)
With the two previous plots, is it possible to compare the different impact categories with each other? Why?
Answer to exercise 2
Environmental impact scores in LCA are expressed in different physical units, so it is not possible to compare the different categories directly.
One solution is to normalize the impacts with respect to a reference system, so that the results are expressed without unit.
To do so, we have to divide our results by the scores obtained for a reference situation (for example, the total impacts resulting from transportation systems in France, in 2023). This enables to get a standard scale to compare the impacts.
In what follows, we use the normalization factors provided by the Environmental Footprint method, which express the average impacts of one european citizen in the year 2010. For example, the normalization factor for the “climate change” category is equal to 8100 kgCO2-eq.
# Read the normalization factors from the excel file
normalization_factors_df = pd.read_excel('https://raw.githubusercontent.com/SizingLab/sizing_course/main/laboratories/Lab-watt_project/assets/data/normalisation_weighting_factors.xlsx', sheet_name='NF SETS')
# Create a copy of the results dataframe and add the normalization factors for each impact category
result_df_normalized = pd.merge(result_df, normalization_factors_df, how='left', on='Impact category')
# Divide each "Impact Score" column by the corresponding normalization factor
for col in [col for col in result_df.columns if 'Impact Score' in col]:
result_df_normalized[col] /= result_df_normalized['Normalization factor']
# Plot the LCA results
ax = result_df_normalized[['Impact Score (Copper)', 'Impact Score (Ferrite)', 'Impact Score (Joules)', 'Impact Score (Friction)']].plot.bar(stacked=True)
ax.set_xticklabels(result_df_normalized['XLabels'])
ax.set_xlabel("Impact Category")
ax.set_ylabel("Normalized Impact Score")
ax.set_title("Normalized Impact Score for Each Impact Category");
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[6], line 2
1 # Plot the LCA results
----> 2 ax = result_df_normalized[['Impact Score (Copper)', 'Impact Score (Ferrite)', 'Impact Score (Joules)', 'Impact Score (Friction)']].plot.bar(stacked=True)
3 ax.set_xticklabels(result_df_normalized['XLabels'])
4 ax.set_xlabel("Impact Category")
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/frame.py:3813, in DataFrame.__getitem__(self, key)
3811 if is_iterator(key):
3812 key = list(key)
-> 3813 indexer = self.columns._get_indexer_strict(key, "columns")[1]
3815 # take() does not accept boolean indexers
3816 if getattr(indexer, "dtype", None) == bool:
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/indexes/base.py:6070, in Index._get_indexer_strict(self, key, axis_name)
6067 else:
6068 keyarr, indexer, new_indexer = self._reindex_non_unique(keyarr)
-> 6070 self._raise_if_missing(keyarr, indexer, axis_name)
6072 keyarr = self.take(indexer)
6073 if isinstance(key, Index):
6074 # GH 42790 - Preserve name from an Index
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/pandas/core/indexes/base.py:6130, in Index._raise_if_missing(self, key, indexer, axis_name)
6128 if use_interval_msg:
6129 key = list(key)
-> 6130 raise KeyError(f"None of [{key}] are in the [{axis_name}]")
6132 not_found = list(ensure_index(key)[missing_mask.nonzero()[0]].unique())
6133 raise KeyError(f"{not_found} not in index")
KeyError: "None of [Index(['Impact Score (Copper)', 'Impact Score (Ferrite)',\n 'Impact Score (Joules)', 'Impact Score (Friction)'],\n dtype='object')] are in the [columns]"
Exercise (Interpretation with normalized results)
Have a look at the normalized results. What impact categories are the most relevant?
10.10.4. 4. Sensitivity analysis#
In the first place, we have assumed that the inductor will be used for \(T_{use}=14,600\) hours during its lifetime. However, this assumption may be too pessimistic or optimistic. The LCA practitioner must always check the sensitivity of the results to the assumptions to ensure the robustness of the study.
Exercise (Sensitivity to lifetime assumption)
Re-run the analysis for different assumptions over the inductors’s lifetime, for example \(T_{use}\) ranging from 10,000 to 20,000 hours. Do you observe any difference?
In the following, we will keep \(T_{use}= 5 \times 365 \times 8 = 14,600\) hours.
10.10.5. 5. Sizing optimization with various environmental objectives#
We will now focus on re-sizing the inductor to minimize the environmental impacts instead of the mass.
To do so, we have to change the objective function in the sizing code.
Exercise (Sizing code modification)
Modify the sizing code to return the environmental impact of the inductor for the requested category.
import numpy as np
import scipy
import scipy.optimize
from math import pi, sqrt
import timeit
import pandas as pd
# Specifications
IL_max=150 # [A] max current
IL_RMS=140 # [A] RMS current
L=150e-6 # [H] Inductance
# Assumptions
#J=5e6 # [A/m²] Current density
B_mag=0.4 # [T] Induction
k_bob=0.33 # [-] winding coefficient
T_amb=60 # [°C] Support temperature
T_max=150 # [°C] Max temperature
# Physical constants
mu_0=4*3.14e-7 # [SI] permeability
# Reference parameters for scaling laws (Pot core)
D_ref=66.29e-3 # [m] External diameter
H_ref=57.3e-3/2 # [m] 1 half core height
Airon_ref=pi/4*(29.19**2-6.5**2)*1e-6 # [m^2] iron surface
Awind_ref=43.28*(54.51-28.19)/2*1e-6 # [m^2] winding surface
Rmoy_ref=(54.51-28.19)/2*1e-3 # [m] Mean radius for winding
M_ref=225e-3 # [kg] 1 half core mass
# Additional parameters useful for the life cycle assessment
T_use = ... # [hrs] lifetime service
D_use = ... # [km] corresponding travel distance
Crr = 0.01 # [-] rolling resistance coefficient
# Database for LCA
database_path = 'https://raw.githubusercontent.com/SizingLab/sizing_course/main/laboratories/Lab-watt_project/assets/data/lca_inductance.xlsx' # Path to the database
df_copper = pd.read_excel(database_path, sheet_name='Copper wire (1 kg)')
df_ferrite = pd.read_excel(database_path, sheet_name='Ferrite (1 kg)')
df_electricity = pd.read_excel(database_path, sheet_name='Electricity France (1 kWh)')
df_plastic = pd.read_excel(database_path, sheet_name='Plastic body (1 kg)')
normalization_factors_df = pd.read_excel('https://raw.githubusercontent.com/SizingLab/sizing_course/main/laboratories/Lab-watt_project/assets/data/normalisation_weighting_factors.xlsx', sheet_name='NF SETS')
# -----------------------
# sizing code
# -----------------------
# inputs:
# - param: optimisation variables vector
# - arg: selection of output
# output:
# - objective if arg='Obj', problem characteristics if arg='Prt', constraints other else
def SizingInductor(param, arg):
# Variables
e_D=param[0] # [m] air gap / External diameter
J=param[1]*1e6 # [A/m²] current density
# Magnetic pi_0
PI0_m=3.86*e_D**(0.344-0.226*np.log10(e_D)-0.0355*(np.log10(e_D))**2)
# Magnetic energy calculation
E_mag=1/2*L*IL_max**2 # [J] Energy
D=(E_mag*2*PI0_m*D_ref**4/J**2/k_bob**2/Awind_ref**2/mu_0)**(1/5) # External diameter calculation
# Reluctance and inductance
RL=PI0_m/mu_0/D # [] reluctance
N=np.sqrt(L*RL) # [-] turn number
# Wire section & winding surface
S_w=IL_RMS/J # [m²] 1 wire section area
S_bob=N*S_w/k_bob # [m^2] winding surface
# Core scaling
A_iron=Airon_ref*(D/D_ref)**(2) # [m^2] iron surface
A_wind=Awind_ref*(D/D_ref)**(2) # [m^2] winding surface
H=H_ref*(D/D_ref)**(1) # [m] 1 half core height
Rmoy=Rmoy_ref*(D/D_ref)**(1) # [m] Mean radius for winding
M_core =M_ref*(D/D_ref)**(3) # [kg] one half core mass
# Magnetic field
B=N*IL_max/RL/A_iron # [T]
# Mass
M_copper=2*pi*Rmoy*N*S_w*7800
M_total=M_copper+M_core*2
# Temperature calculation
PI0_t = 0.0786 + 0.524*e_D -2.04*e_D**2 # PI0 thermal
Rth=PI0_t/(0.5*D) # [K/W] thermal resistance
PJ=J**2*2*pi*Rmoy*N*S_w*1.7e-8 # [W] Joules losses
Teta_hot=T_amb + PJ*Rth # [°C] Hot spot temperature
# Energy losses
E_PJ = ... # [kWh] Joule losses over the life cycle of the inductor
E_fr = ... # [kWh] friction losses (at bus level) due to the inductor's mass
E_total = E_PJ + E_fr
# Objective and contraints
if arg=='mass':
return M_total
elif arg=='energy':
return E_total / 100 # factor 100 to facilitate optimization convergence (result closer to unity)
elif arg in ["acidification",
"climate change",
"ecotoxicity: freshwater",
"energy resources: non-renewable",
"eutrophication: freshwater",
"eutrophication: marine",
"eutrophication: terrestrial",
"human toxicity: carcinogenic",
"human toxicity: non-carcinogenic",
"ionising radiation: human health",
"land use",
"material resources: metals/minerals",
"ozone depletion",
"particulate matter formation",
"photochemical oxidant formation: human health",
"water use"
]:
# total impact for the requested impact category
impact_score = (
... * df_copper[df_copper["Impact category"] == arg]["Impact Score"] +
... * df_ferrite[df_ferrite["Impact category"] == arg]["Impact Score"] +
... * df_electricity[df_electricity["Impact category"] == arg]["Impact Score"]
)
# Normalize the score (not mandatory but may facilitates optimization because objective value is closer to unity)
normalization_factor = normalization_factors_df[normalization_factors_df["Impact category"] == arg]["Normalization factor"].values[0]
normalized_score = impact_score / normalization_factor
return normalized_score
elif arg=='Prt':
print("* Optimisation variables:")
print(" Airgap e/D = %.2g"% (e_D))
print(" Current density J = %.2g"% (J))
print("* Components characteristics:")
print(" Total mass = %.2f kg" % M_total)
print(" Core (2) mass = %.2f kg" % (2*M_core))
print(" Coil mass = %.2f kg" % M_copper)
print(" Core dimensions = %.1f (diameter) x %.1f (heigth) mm"%((D*1e3,2*H*1e3)))
print(" Airgap e = %.1f mm"%(e_D*D*1e3))
print(" A_iron = %.0f mm^2"%(A_iron*1e6))
print(" Number of turns = %i"%(N))
print(" Joules losses = %.3f kWh" %(E_PJ))
print(" Friction losses = %.3f kWh" %(E_fr))
print(" Total energy losses = %.3f kWh" %(E_total))
print("* Constraints (should be >0):")
print(" Winding surface margin = %.3f mm²" % ((A_wind-S_bob)*1e6))
print(" Induction margin = %.3f T" %((B_mag-B)))
print(" Temperature margin = %.3f K" %(T_max-Teta_hot))
else:
return [A_wind-S_bob, B_mag-B, T_max-Teta_hot]
We can now re-run the optimization to size the inductor with respect to different objective functions.
Exercise (Comparison of objective functions)
Run the optimization with the following objective functions:
- Mass minimization
- Energy losses minimization
- Impact score minimization for each environmental category.
Store the sizing results (e.g., core mass and coil mass) in theoptimization_dictobject and plot the results.
Are the results always the same? Provide an explanation based on the LCA study carried out earlier.
# Optimization variables
e_D=1e-3 # [m] airgap
J=50 # [A/mm²] current density
# Vector of parameters
parameters = np.array((e_D,J))
# Optimization with SLSQP algorithm
contrainte=lambda x: SizingInductor(x, 'Const')
objectif=lambda x: SizingInductor(x, 'mass') # To modify according to the objective function (e.g., 'climate change')
result = scipy.optimize.fmin_slsqp(func=objectif, x0=parameters,
bounds=[(1e-3,1e-1),(1,50)],
f_ieqcons=contrainte, iter=100, acc=1e-6)
# Final characteristics after optimization
print("-----------------------------------------------")
print("Final characteristics after optimization :")
SizingInductor(result, 'Prt')
print("-----------------------------------------------")
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[8], line 11
9 contrainte=lambda x: SizingInductor(x, 'Const')
10 objectif=lambda x: SizingInductor(x, 'mass') # To modify according to the objective function (e.g., 'climate change')
---> 11 result = scipy.optimize.fmin_slsqp(func=objectif, x0=parameters,
12 bounds=[(1e-3,1e-1),(1,50)],
13 f_ieqcons=contrainte, iter=100, acc=1e-6)
15 # Final characteristics after optimization
16 print("-----------------------------------------------")
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/scipy/optimize/_slsqp_py.py:210, in fmin_slsqp(func, x0, eqcons, f_eqcons, ieqcons, f_ieqcons, bounds, fprime, fprime_eqcons, fprime_ieqcons, args, iter, acc, iprint, disp, full_output, epsilon, callback)
206 if f_ieqcons:
207 cons += ({'type': 'ineq', 'fun': f_ieqcons, 'jac': fprime_ieqcons,
208 'args': args}, )
--> 210 res = _minimize_slsqp(func, x0, args, jac=fprime, bounds=bounds,
211 constraints=cons, **opts)
212 if full_output:
213 return res['x'], res['fun'], res['nit'], res['status'], res['message']
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/scipy/optimize/_slsqp_py.py:338, in _minimize_slsqp(func, x0, args, jac, bounds, constraints, maxiter, ftol, iprint, disp, eps, callback, finite_diff_rel_step, **unknown_options)
334 # Set the parameters that SLSQP will need
335 # meq, mieq: number of equality and inequality constraints
336 meq = sum(map(len, [atleast_1d(c['fun'](x, *c['args']))
337 for c in cons['eq']]))
--> 338 mieq = sum(map(len, [atleast_1d(c['fun'](x, *c['args']))
339 for c in cons['ineq']]))
340 # m = The total number of constraints
341 m = meq + mieq
File /opt/hostedtoolcache/Python/3.9.25/x64/lib/python3.9/site-packages/scipy/optimize/_slsqp_py.py:338, in <listcomp>(.0)
334 # Set the parameters that SLSQP will need
335 # meq, mieq: number of equality and inequality constraints
336 meq = sum(map(len, [atleast_1d(c['fun'](x, *c['args']))
337 for c in cons['eq']]))
--> 338 mieq = sum(map(len, [atleast_1d(c['fun'](x, *c['args']))
339 for c in cons['ineq']]))
340 # m = The total number of constraints
341 m = meq + mieq
Cell In[8], line 9, in <lambda>(x)
6 parameters = np.array((e_D,J))
8 # Optimization with SLSQP algorithm
----> 9 contrainte=lambda x: SizingInductor(x, 'Const')
10 objectif=lambda x: SizingInductor(x, 'mass') # To modify according to the objective function (e.g., 'climate change')
11 result = scipy.optimize.fmin_slsqp(func=objectif, x0=parameters,
12 bounds=[(1e-3,1e-1),(1,50)],
13 f_ieqcons=contrainte, iter=100, acc=1e-6)
Cell In[7], line 101, in SizingInductor(param, arg)
99 E_PJ = ... # [kWh] Joule losses over the life cycle of the inductor
100 E_fr = ... # [kWh] friction losses (at bus level) due to the inductor's mass
--> 101 E_total = E_PJ + E_fr
103 # Objective and contraints
104 if arg=='mass':
TypeError: unsupported operand type(s) for +: 'ellipsis' and 'ellipsis'
# Record the mass corresponding to the inductor obtained with each optimization objective
optimization_dict = {}
optimization_dict["mass"] = [2.88, 0.72] # [kg] (core mass, coil mass)
optimization_dict["energy"] = [10.96, 2.76] # [kg]
optimization_dict["acidification"] = ...
optimization_dict["climate change"] = ...
optimization_dict["ecotoxicity: freshwater"] = ...
optimization_dict["energy resources: non-renewable"] = ...
optimization_dict["eutrophication: freshwater"] = ...
optimization_dict["eutrophication: marine"] = ...
optimization_dict["eutrophication: terrestrial"] = ...
optimization_dict["human toxicity: carcinogenic"] = ...
optimization_dict["human toxicity: non-carcinogenic"] = ...
optimization_dict["ionising radiation: human health"] = ...
optimization_dict["land use"] = ...
optimization_dict["material resources: metals/minerals"] = ...
optimization_dict["ozone depletion"] = ...
optimization_dict["particulate matter formation"] = ...
optimization_dict["photochemical oxidant formation: human health"] = ...
optimization_dict["water use"] = ...
# Plot the sizing results obtained with each optimization objective
import matplotlib.pyplot as plt
optimization_objectives = []
values = []
for key, val in optimization_dict.items():
optimization_objectives.append(key)
values.append(val)
values = np.array(values)
fig, ax = plt.subplots()
ax.bar(range(len(optimization_objectives)), values[:,0], label="core mass") # Core masses
ax.bar(range(len(optimization_objectives)), values[:,1], bottom=values[:,0], label="coil mass") # Add coil masses
plt.xticks(range(len(optimization_objectives)), optimization_objectives, rotation='vertical')
ax.set_xlabel('Optimization objective')
ax.set_ylabel('Inductor Mass [kg]')
ax.set_title('Inductor mass obtained with different optimization objectives')
plt.legend()
plt.xticks(rotation='vertical')
plt.show()
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[10], line 9
7 optimization_objectives.append(key)
8 values.append(val)
----> 9 values = np.array(values)
11 fig, ax = plt.subplots()
12 ax.bar(range(len(optimization_objectives)), values[:,0], label="core mass") # Core masses
ValueError: setting an array element with a sequence. The requested array has an inhomogeneous shape after 1 dimensions. The detected shape was (18,) + inhomogeneous part.
Exercise (Design decision)
Propose a strategy to make a decision about which sizing should be used for the inductor. Should we select the inductor with lowest mass? the one that minimizes climate change? …
10.10.6. 6. Multi-objective optimization#
The multi-objective optimization consists in having a single objective function that is expressed as a weighted sum of all the categories of environmental impact. This results in a single environmental score:
where \({NS}_i\) is the normalized score obtained for the i-th impact category (1 = acidification, 2 = climate change, and so on) and \(w_i\) is a weighting factor that represents the (subjective) importance accorded to this category.
Similarly to the normalization factors, the Environmental Footprint method provides a set of weighting factors for each impact category. Note that process for obtaining these weighting factors is rather subjective, as it suppose to rank very different environmental impacts. It can include criteria such as the reversibility of the impacts, the geographic spread of the impact and its time span.
The weighting factors \(w_i\) proposed by the Environmental Footprint method are provided in an excel document and displayed below:
# Import weighting factors
weighting_factors_df = pd.read_excel('https://raw.githubusercontent.com/SizingLab/sizing_course/main/laboratories/Lab-watt_project/assets/data/normalisation_weighting_factors.xlsx', sheet_name='WF SETS')
weighting_factors_df
| Impact category | Weighting factor | |
|---|---|---|
| 0 | acidification | 0.0620 |
| 1 | climate change | 0.2106 |
| 2 | ecotoxicity: freshwater | 0.0192 |
| 3 | eutrophication: freshwater | 0.0280 |
| 4 | eutrophication: marine | 0.0296 |
| 5 | eutrophication: terrestrial | 0.0371 |
| 6 | human toxicity: carcinogenic | 0.0213 |
| 7 | human toxicity: non-carcinogenic | 0.0184 |
| 8 | ionising radiation: human health | 0.0501 |
| 9 | land use | 0.0794 |
| 10 | ozone depletion | 0.0631 |
| 11 | particulate matter formation | 0.0896 |
| 12 | photochemical oxidant formation: human health | 0.0478 |
| 13 | energy resources: non-renewable | 0.0832 |
| 14 | material resources: metals/minerals | 0.0755 |
| 15 | water use | 0.0851 |
Now, we have to update the sizing code to calculate and return the single environmental score. The modified code is provided:
import numpy as np
import scipy
import scipy.optimize
from math import pi, sqrt
import timeit
import pandas as pd
# Specifications
IL_max=150 # [A] max current
IL_RMS=140 # [A] RMS current
L=150e-6 # [H] Inductance
# Assumptions
#J=5e6 # [A/m²] Current density
B_mag=0.4 # [T] Induction
k_bob=0.33 # [-] winding coefficient
T_amb=60 # [°C] Support temperature
T_max=150 # [°C] Max temperature
# Physical constants
mu_0=4*3.14e-7 # [SI] permeability
# Reference parameters for scaling laws (Pot core)
D_ref=66.29e-3 # [m] External diameter
H_ref=57.3e-3/2 # [m] 1 half core height
Airon_ref=pi/4*(29.19**2-6.5**2)*1e-6 # [m^2] iron surface
Awind_ref=43.28*(54.51-28.19)/2*1e-6 # [m^2] winding surface
Rmoy_ref=(54.51-28.19)/2*1e-3 # [m] Mean radius for winding
M_ref=225e-3 # [kg] 1 half core mass
# Additional parameters useful for the life cycle assessment
T_use = 5*365*8 # [hrs] lifetime service
D_use = 300000 # [km] corresponding travel distance
Crr = 0.01 # [-] rolling resistance coefficient
# Database for LCA
database_path = 'https://raw.githubusercontent.com/SizingLab/sizing_course/main/laboratories/Lab-watt_project/assets/data/lca_inductance.xlsx' # Path to the database
df_copper = pd.read_excel(database_path, sheet_name='Copper wire (1 kg)')
df_ferrite = pd.read_excel(database_path, sheet_name='Ferrite (1 kg)')
df_electricity = pd.read_excel(database_path, sheet_name='Electricity France (1 kWh)')
df_plastic = pd.read_excel(database_path, sheet_name='Plastic body (1 kg)')
normalization_factors_df = pd.read_excel('https://raw.githubusercontent.com/SizingLab/sizing_course/main/laboratories/Lab-watt_project/assets/data/normalisation_weighting_factors.xlsx', sheet_name='NF SETS')
weighting_factors_df = pd.read_excel('https://raw.githubusercontent.com/SizingLab/sizing_course/main/laboratories/Lab-watt_project/assets/data/normalisation_weighting_factors.xlsx', sheet_name='WF SETS')
# -----------------------
# sizing code
# -----------------------
# inputs:
# - param: optimisation variables vector
# - arg: selection of output
# output:
# - objective if arg='Obj', problem characteristics if arg='Prt', constraints other else
def SizingInductor(param, arg):
# Variables
e_D=param[0] # [m] air gap / External diameter
J=param[1]*1e6 # [A/m²] current density
# Magnetic pi_0
PI0_m=3.86*e_D**(0.344-0.226*np.log10(e_D)-0.0355*(np.log10(e_D))**2)
# Magnetic energy calculation
E_mag=1/2*L*IL_max**2 # [J] Energy
D=(E_mag*2*PI0_m*D_ref**4/J**2/k_bob**2/Awind_ref**2/mu_0)**(1/5) # External diameter calculation
# Reluctance and inductance
RL=PI0_m/mu_0/D # [] reluctance
N=np.sqrt(L*RL) # [-] turn number
# Wire section & winding surface
S_w=IL_RMS/J # [m²] 1 wire section area
S_bob=N*S_w/k_bob # [m^2] winding surface
# Core scaling
A_iron=Airon_ref*(D/D_ref)**(2) # [m^2] iron surface
A_wind=Awind_ref*(D/D_ref)**(2) # [m^2] winding surface
H=H_ref*(D/D_ref)**(1) # [m] 1 half core height
Rmoy=Rmoy_ref*(D/D_ref)**(1) # [m] Mean radius for winding
M_core =M_ref*(D/D_ref)**(3) # [kg] one half core mass
# Magnetic field
B=N*IL_max/RL/A_iron # [T]
# Mass
M_copper=2*pi*Rmoy*N*S_w*7800
M_total=M_copper+M_core*2
# Temperature calculation
PI0_t = 0.0786 + 0.524*e_D -2.04*e_D**2 # PI0 thermal
Rth=PI0_t/(0.5*D) # [K/W] thermal resistance
PJ=J**2*2*pi*Rmoy*N*S_w*1.7e-8 # [W] Joules losses
Teta_hot=T_amb + PJ*Rth # [°C] Hot spot temperature
# Energy losses
E_PJ = T_use * (PJ / 1000) # [kWh] Joule losses over the life cycle of the inductor
E_fr = M_total * 9.81 * Crr * (D_use * 1000) / 1000 / 3600 # [kWh] friction losses (at bus level) due to the inductor's mass
E_total = E_PJ + E_fr
# Objective and contraints
if arg=='mass':
return M_total
elif arg=='energy':
return E_total / 100 # factor 100 to facilitate optimization convergence (result closer to unity)
elif arg in ["acidification",
"climate change",
"ecotoxicity: freshwater",
"energy resources: non-renewable",
"eutrophication: freshwater",
"eutrophication: marine",
"eutrophication: terrestrial",
"human toxicity: carcinogenic",
"human toxicity: non-carcinogenic",
"ionising radiation: human health",
"land use",
"material resources: metals/minerals",
"ozone depletion",
"particulate matter formation",
"photochemical oxidant formation: human health",
"water use"
]:
# total impact for the requested impact category
impact_score = (
M_copper * df_copper[df_copper["Impact category"] == arg]["Impact Score"] +
2*M_core * df_ferrite[df_ferrite["Impact category"] == arg]["Impact Score"] +
E_total * df_electricity[df_electricity["Impact category"] == arg]["Impact Score"]
)
# Normalize the score (not mandatory but may facilitates optimization because objective value is closer to unity)
normalization_factor = normalization_factors_df[normalization_factors_df["Impact category"] == arg]["Normalization factor"].values[0]
normalized_score = impact_score / normalization_factor
return normalized_score
elif arg == 'ecodesign': # multi-objective environmental objective
single_score = 0
# Calculate the impact for the each impact category
for impact_category in weighting_factors_df["Impact category"].values:
impact_score = (
M_copper * df_copper[df_copper["Impact category"] == impact_category]["Impact Score"] +
2*M_core * df_ferrite[df_ferrite["Impact category"] == impact_category]["Impact Score"] +
E_total * df_electricity[df_electricity["Impact category"] == impact_category]["Impact Score"]
)
# Normalize then weight the score
normalization_factor = normalization_factors_df[normalization_factors_df["Impact category"] == impact_category]["Normalization factor"].values[0]
normalized_score = impact_score / normalization_factor
weighting_factor = weighting_factors_df[weighting_factors_df["Impact category"] == impact_category]["Weighting factor"].values[0]
weighted_score = normalized_score.values[0] * weighting_factor
# Add to the single environmental score
single_score += weighted_score
return single_score
elif arg=='Prt':
print("* Optimisation variables:")
print(" Airgap e/D = %.2g"% (e_D))
print(" Current density J = %.2g"% (J))
print("* Components characteristics:")
print(" Total mass = %.2f kg" % M_total)
print(" Core (2) mass = %.2f kg" % (2*M_core))
print(" Coil mass = %.2f kg" % M_copper)
print(" Core dimensions = %.1f (diameter) x %.1f (heigth) mm"%((D*1e3,2*H*1e3)))
print(" Airgap e = %.1f mm"%(e_D*D*1e3))
print(" A_iron = %.0f mm^2"%(A_iron*1e6))
print(" Number of turns = %i"%(N))
print(" Joules losses = %.3f kWh" %(E_PJ))
print(" Friction losses = %.3f kWh" %(E_fr))
print(" Total energy losses = %.3f kWh" %(E_total))
print("* Constraints (should be >0):")
print(" Winding surface margin = %.3f mm²" % ((A_wind-S_bob)*1e6))
print(" Induction margin = %.3f T" %((B_mag-B)))
print(" Temperature margin = %.3f K" %(T_max-Teta_hot))
else:
return [A_wind-S_bob, B_mag-B, T_max-Teta_hot]
10.10.6.1. Results for the eco-design#
# Optimization variables
e_D=1e-3 # [m] airgap
J=50 # [A/mm²] current density
# Vector of parameters
parameters = np.array((e_D,J))
# Optimization with SLSQP algorithm
contrainte=lambda x: SizingInductor(x, 'Const')
objectif=lambda x: SizingInductor(x, 'ecodesign')
result = scipy.optimize.fmin_slsqp(func=objectif, x0=parameters,
bounds=[(1e-3,1e-1),(1,50)],
f_ieqcons=contrainte, iter=100, acc=1e-6)
# Final characteristics after optimization
print("-----------------------------------------------")
print("Final characteristics after optimization :")
SizingInductor(result, 'Prt')
print("-----------------------------------------------")
Optimization terminated successfully (Exit mode 0)
Current function value: 0.026892673532935087
Iterations: 16
Function evaluations: 48
Gradient evaluations: 16
-----------------------------------------------
Final characteristics after optimization :
* Optimisation variables:
Airgap e/D = 0.027
Current density J = 3.2e+06
* Components characteristics:
Total mass = 5.77 kg
Core (2) mass = 4.61 kg
Coil mass = 1.16 kg
Core dimensions = 144.0 (diameter) x 124.5 (heigth) mm
Airgap e = 3.9 mm
A_iron = 3002 mm^2
Number of turns = 18
Joules losses = 370.619 kWh
Friction losses = 47.203 kWh
Total energy losses = 417.823 kWh
* Constraints (should be >0):
Winding surface margin = 179.210 mm²
Induction margin = -0.000 T
Temperature margin = 57.840 K
-----------------------------------------------
10.10.6.2. Comparison of the environmental impacts between the “light” inductor and the “eco-designed” one.#
def impact_score(impact_category, M_core, M_copper, E_total):
"""
Calculate the LCA score of the inductor for a given impact category.
Parameters:
- impact_category: str, the impact category for which to calculate the total impact score.
- M_copper: float, the mass of copper in the inductor (kg)
- M_core: float, the mass of ferrite in the inductor (kg)
- E_total: float, the total energy losses (kWh)
Returns:
- normalized_score: float, the normalized impact score for the given impact category.
"""
# impact for the requested impact category
impact_score = (
M_copper * df_copper[df_copper["Impact category"] == impact_category]["Impact Score"] +
2*M_core * df_ferrite[df_ferrite["Impact category"] == impact_category]["Impact Score"] +
E_total * df_electricity[df_electricity["Impact category"] == impact_category]["Impact Score"]
)
# Normalize then weight the score
normalization_factor = normalization_factors_df[normalization_factors_df["Impact category"] == impact_category]["Normalization factor"].values[0]
normalized_score = impact_score / normalization_factor
weighting_factor = weighting_factors_df[weighting_factors_df["Impact category"] == impact_category]["Weighting factor"].values[0]
weighted_score = normalized_score.values[0] * weighting_factor
return weighted_score
# List of impact categories
impact_categories = result_df['Impact category'].unique()
# Impacts for the inductor with lowest mass
impacts_mass_obj = {category: impact_score(category, 2.88, 0.72, 841.951) for category in impact_categories}
# Impacts for the inductor with lowest single environmental score
impacts_eco_obj = {category: impact_score(category, 4.61, 1.16, 417.823) for category in impact_categories}
# Bar plot comparing the results
bar_width = 0.35
index = np.arange(len(impact_categories))
fig, ax = plt.subplots()
bar1 = ax.bar(index, impacts_mass_obj.values(), bar_width, label='Mass objective')
bar2 = ax.bar(index + bar_width, impacts_eco_obj.values(), bar_width, label='Environmental objective')
# Add labels, title, and legend
ax.set_xlabel('Impact Category')
ax.set_ylabel('Normalized and Weighted Impact Scores')
ax.set_title('Impact Scores obtained with the mass objective and the environmental objective')
ax.set_xticks(index + bar_width / 2)
ax.set_xticklabels(impact_categories)
ax.legend()
plt.xticks(rotation='vertical')
# Show the plot
plt.show()
10.10.7. Appendix#
